Spring Data JPA선택한 이유와 다른 JDBC 라이브러리 비교
JDBC(Java Database Conncetor)
- 1997년 자바와 데이터 베이스 연결해주는 하나의 라이브러리 -> 온라인 비즈니스가 성장해서 DB의 중요성을 인지
- 연결 순서
- Driver Manager : database type에 맞게 설정 (Oracle, Mysql 등을 선택 하여 해당 DB관련 객체 생성)
- Connection : schema와 DB주소 연결
- STMT : query 문 삽입
- ResultSet : 결과 수렴
- 불편한 점 : 중복 코드 많음(Manager 생성, connection 코드 작성 등), 쿼리를 일일이 써야함, connection관리를 일일히 해야함
SQL Mapper
- Spring JDBC
- JDBC template에 DataSource를 주입시켜주고 해당 JDBC Template객체만 사용 -> config 에 맞게 주입 해준다 -> Spring boot 는 application.propertis에 설정 -> DB과제 이 라이브러리 사용함
- 예외 처리, 트랜젝션 처리, 결과에 대한 루프처리, reset, stmt 등 닫기 기능을 자동으로 제공하는 장점이 있음
- IBatis/MyBatis
- SQL를 분리하는 것 : Query를 Java 내부 코드에서 xml로 옮기서 작업함
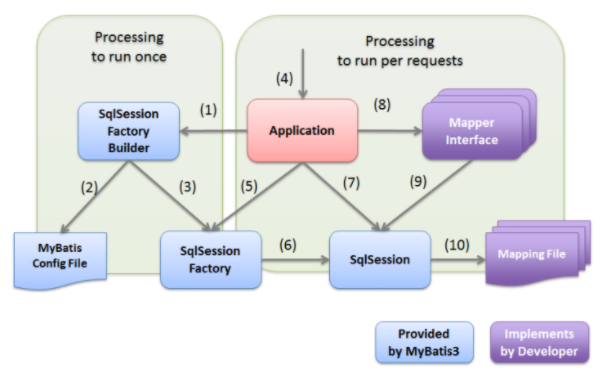
- 초기 mybatis config file로 부터 session생성
- session에 mapper로 하나의 interface로 연결
- method에 query를 mapping 해준다.
- ORM(Object Relational Mapping)
- 정의 : 객체지향으로 구현되어있는 것을 RDBMS에 Mapping 시키기 위한 기술 -> SQL문에 의존적인 개발을 방지하기위해서 사용하게됨
- JPA : interface와 같다
- 구현체
- Hibernate
- EclipseLink
- DataNucleus
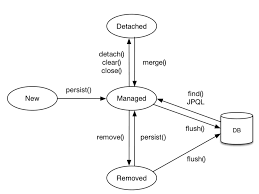
- Entity 생명주기
- Eneity Manager : 새로운 data가 있다면 save 함수로 인해 persistence context에 올라가게되고 이러한 data를 관리해주는 역할을 담당
- Flush 과정에서 SQL문 생성 -> 최종적으로 Transaction이 끝나면 flush 하는 형태
- 핵심 기술
- Lazy Loading : 필요한 때 해당 데이터를 query로 호출 -> 사용하지 않을 경우 불필요한 join연산 등을 방지(Proxy 패턴을 사용)
- Dirty Checking : 바로 DB에 업데이트하지 않고 일단 메모리상에 처리한 결과를 저장 -> Transaction이 끝나면 그때 DB에 쿼리를 날려 저장 및 삭제를 한다.
- Caching : 최근 자주 사용되는 데이터는 메모리에 계속 상주해 있도록 유도
- Spring Data JPA : spring data 전형에서 만든 JPA
- Repository를 제안 : 한단계 더 추상화 된 형태 -> Entity Manager를 자동으로 함수명에 맞게 mapping해준다.
반성 과 삽질
- 반성 : ORM을 사용했다 Spring Data JPA를 사용하면서 편리한 요소만 봤었다.
- 문제점 : JPA N + 1문제 발생 -> 전 회고록 참고
- 극복 과정에 있다 지금 현재 JPA관련 책을 사서 공부중이다 그리고 공부한 내용을 블로그에 올리고 있다.
- @OneToMany인 경우 Mappedby와 같이 양방향과 일반 적인 단방향에 주의 해야한다. 이 것은 추 후에 JPA 카테고리에서 다루도록 하겠습니다.
- JPA N+1극복을 위해 지금 현재 공부중이고 이것을 극복하지 못한다면 Mybatis나 Spring JDBC를 사용해야한다고 생각합니다.